

Norma categorial para el español de Bogotá, Colombia
Category norm for the Spanish spoken in Bogota, Colombia

Battig, W. F. y Montague, W. E. (1969). ‘Category norms of verbal items in 56 categories: A replication and extension of the Connecticut category norms’. Journal of Experimental Psychology, 80, 1-46.
Dubois, D. y Poitou, J. (2002). ‘Normes catégorielles pour 22 catégories sémantiques du français et 10 catégories sémantiques de l’allemand’. Cahiers du LCPE, 5, 35-118.
Goikoetxea, E. (2000). ‘Frecuencia de producción de las respuestas a 52 categorías verbales en niños de primaria’. Psicológica, 21, 61-89.
Mateus, G. y Santiago, A. (2006). ‘Disponibilidad léxica en estudiantes bogotanos’. Folios, 24, 3-26. Bogotá: Universidad Pedagógica Nacional.
Pascual, J. L. y Musitu, G. O. (1980). Normas categoriales. Psicológica, 1, 157–174.
Ruts, W., De Deyne, S., Ameel, E., Vanpaemel, W., Verbeemen, T. y Storms, G. (2004). ‘Dutch norm data for 13 semantic categories and 338 exemplars’. Behavior Research Methods, Instruments, y Computers. 36 (3), 506-515.
Yoon, C., Feinberg, F., Hall, A., Hedden, T., Chen, H., Jing, Q., Cui, Y., y Park, D. (2004). ‘Category Norms as a Function of Culture and Age: Comparisons of Item Responses to 105 Categories by American and Chinese Adults. Psychology and Aging’. Vol. 19, nº. 3, 379-393.
APA
ACM
ACS
ABNT
Chicago
Harvard
IEEE
MLA
Turabian
Vancouver
Descargar cita
Citaciones
1. Macarena Martínez Cuitiño, Dolores Jazmín Zamora, Natalia Rocío Camilotto, Nicolás Nahuel Romero, Diego Shalóm. (2024). Normas para 70 categorías semánticas obtenidas de adolescentes hablantes del español rioplatense. Revista de Investigación en Logopedia, 14(1), p.e86859. https://doi.org/10.5209/rlog.86859.
2. Vicenta Reynoso-Alcántara, Juan Silva-Pereyra, Samana Vergara-Lope Tristán, José Enrique Díaz Camacho, María Isabel Guiot Vázquez, Diana Donají del Callejo Canal, Margarita Edith Canal Martínez. (2019). Verbal fluency in Mexican Spanish-speaking subjects with high educational level: Ranking of letters and semantic categories. Journal of Clinical and Experimental Neuropsychology, 41(10), p.1001. https://doi.org/10.1080/13803395.2019.1643454.
Métricas PlumX
Visitas
Descargas
Norma categorial para el español de Bogotá, Colombia
Category norm for the Spanish spoken in Bogota, Colombia
1Magíster en Lingüística, Universidad Nacional de Colombia. Profesor, Institución Universitaria Colombo Americana. angelram@yahoo.com.
1M.A. en Lingüística. Profesor Asistente, Universidad Nacional de Colombia. napardog@unal.edu.co.
Artículo recibido el 23 de Febrero de 2010 y aprobado el 30 de Agosto de 2010.
Resumen
En este trabajo presentamos los resultados de un estudio elaborado en Bogotá con 210 estudiantes universitarios de 5 instituciones con diferentes características sociodemográficas, con el fin de establecer las normas categoriales léxicas. Se utilizaron las 56 categorías léxico-semánticas usadas en el clásico estudio de Battig y Motague (1969) y se recogieron más de 7800 palabras que fueron organizadas por rango y moda.
En la revisión bibliográfica realizada no se encontraron trabajos de esta naturaleza para el español colombiano (o latinoamericano), y se espera que sus resultados sean usados en protocolos para el campo de la terapia del lenguaje y los estudios psicolingüísticos. Los datos recogidos fueron comparados con uno de los estudios de norma categorial realizados para el español ibérico.
Palabras clave: Norma categorial, psicolingüística, categoría léxica, español de Bogotá.
Abstract
In this article, we present the results of a study carried out in Bogotá, Colombia with 210 university students from five different universities pertaining to diverse socio-demographic groups. The objective of the study was to establish the lexical category norms. 56 lexical-semantic categories used by Battig and Montague (1969) in their classic study were employed. More than 7800 words were collected and organized by range and mode. There are no other studies on this subject for Colombian or Latin American Spanish. We hope that the results presented here will be used both in psycholinguistic and language therapy studies. The collected data were compared to one of the category norm studies made for European Spanish.
Key words: Category norm, psycholinguistics, lexical category, Bogotá Spanish.
Introducción
Desde la década de los 60 los resultados de los estudios de tipicalidad léxica han sido usados en diversas tareas, que van desde trabajos psicológicos–memoria, disponibilidad léxica, etc. –pasando por protocolos de terapia del lenguaje, hasta llegar a investigaciones de corte más lingüístico. Los primeros trabajos (Battig y Montague, 1969) fueron realizados en inglés norteamericano, después, se han realizado diversas adaptaciones e interpretaciones en lenguas tipológicamente diferentes.
Así, encontramos trabajos sobre tipicalidad en francés (Dubois y Poitou, 2002), holandés (Ruts, et al, 2004), alemán (Dubois y Poitou, 2002) y español ibérico (Goikoetxea, 2000, Pascual y Musitu, 1980). Además, existen trabajos comparados que establecen paralelos en aspectos específicos, como el de Yoon (2004) que analiza la variabilidad léxica en distintos grupos etáreos en el chino y el inglés americano.
Las normas categoriales son compilaciones de las respuestas más comunes de un sujeto hablante de una lengua determinada cuando se le pide un ejemplar de alguna categoría semántica (Ejemplo: Un color: azul). El objetivo de estos inventarios es proporcionar datos que puedan ser utilizados en procedimientos de reconocimiento semántico, en los cuales se utilicen las palabras de la compilación para evocar rasgos determinados de su significado.
Por ejemplo, si se le pregunta a una persona por la categoría a la que pertenece la palabra paloma, lo más probable es que asocie esta palabra al grupo de las aves. De otro lado, un ave menos prototípica como la gallina podría ser clasificada más fácilmente dentro del grupo de los animales que dentro de aquel de las aves.
Hasta el momento no se han realizado investigaciones de esta índole para el español colombiano, solamente existe un estudio sobre la disponibilidad léxica en estudiantes bogotanos (Mateus y Santiago 2006); sin embargo, esta investigación no toca el fenómeno de la prototipicalidad. De hecho, no se encontraron estudios de normas categoriales léxicas para las variedades del español hablado en Latinoamérica. Este trabajo es el primer estudio sistemático de prototipicalidad léxica para el español de Colombia.
Método
Participantes
Se escogieron 210 alumnos de las carreras de lenguas extranjeras de 5 universidades de Bogotá; estudiantes de la misma carrera para evitar que el área de conocimiento específico se convierta en una variable, tal como se ha hecho en estudios anteriores. A continuación se presentan las universidades seleccionadas, el número de participantes de cada una y el porcentaje al cual equivale este número con respecto al total de la muestra: Universidad Nacional de Colombia (35) (16.7%), Pontificia Universidad Javeriana (77) (36.7%), Universidad de la Salle (42) (20%), Institución Universitaria Colombo Americana (50) (23.8%) y Universidad de los Andes (6) (2.8%).
Estas universidades se seleccionaron porque sus alumnos pertenecen a grupos socioeconómicos muy diversos. 83 participantes fueron hombres (39.5%) y 127 fueron mujeres (60.5%). Los sujetos se encontraban en el rango de 16 a 44 años de edad; la edad promedio fue de 21.74 (± 4.23). Se incluyeron participantes de diferentes estratos socioeconómicos de la ciudad: estrato 1 (7) (3.3%), estrato 2 (50) (23.8%), estrato 3 (83) (39.5%), estrato 4 (53) (25.2%), estrato 5 (10) (4.8%), estrato 6 (7) (3.3%).
Procedimiento
Esta investigación se llevó a cabo con el mismo procedimiento usado por Battig y Montague (1969), utilizando las mismas categorías del citado estudio para que los resultados puedan compararse con ésta y otras investigaciones de la misma naturaleza.
Los sujetos se encontraban sentados en un salón de clase y a cada uno de ellos se le proporcionó un cuadernillo de 80 hojas y un esfero. Inicialmente, se le pidió a los sujetos que lo abrieran y escribieran sus datos personales: nombre, edad, sexo, estrato socioeconómico3 y universidad, a continuación, el investigador procedió a dar las instrucciones.
En primer lugar, el investigador decía el nombre de una categoría diferente de las 56 estudiadas. Los sujetos comenzaban a escribir ejemplos de la categoría mientras que el investigador revisaba de manera individual las respuestas dadas por los participantes con el fin de verificar la comprensión correcta de las instrucciones por parte de los mismos.
Se les informó que solamente se aceptaban palabras en español que no fueran abreviaturas (dado que los sujetos estudiaban lenguas modernas), pero que sí se aceptaban siglas y marcas comerciales. Las categorías siempre fueron presentadas en el mismo orden, el cual ha sido usado en otros estudios, lo que evita que las respuestas varíen de acuerdo a la posición dada a la categoría en las diferentes fases de recolección de datos.
En segundo lugar, el investigador debía decir el nombre de una categoría específica, por ejemplo "frutas", desde el momento en el que este evento ocurría, los sujetos contaban con 30 segundos para escribir el mayor número posible de ejemplos de la categoría específica. Al término de los 30 segundos el investigador pedía que los sujetos dejaran de escribir y pasaran la hoja; inmediatamente después, decía el nombre de la categoría siguiente. Este proceso se repitió 56 veces, una vez para cada categoría. Al finalizar la lista de categorías, los sujetos debían entregar los cuadernillos para su posterior análisis.
Resultados
Todas las respuestas legibles dadas por los sujetos en cada categoría fueron ordenadas y sistematizadas para su posterior análisis estadístico. Los datos obtenidos de los estratos socioeconómicos 1 al 3 fueron analizados por separado de aquellos de los estratos 4 al 6, con el fin de realizar una correlación entre la variable clase social y las respuestas obtenidas.
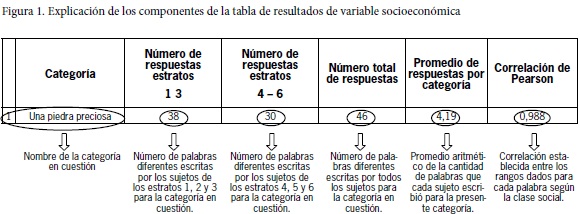
A continuación se presentará la tabla de información general, que resume los datos obtenidos en cada categoría; tiene seis columnas, en la primera está la categoría que se elicita; la segunda y tercera columnas ofrecen el número total de palabras diferentes escritas por los sujetos, clasificadas según el grupo socioeconómico; en la cuarta columna se presenta el número de palabras diferentes escritas por todos los sujetos para la categoría en cuestión.
En la quinta columna se puede observar el promedio de palabras escritas para esta categoría específica; y, finalmente, en la sexta columna se aprecia la correlación de Pearson realizada entre los rangos, es decir, la ubicación promedio de cada palabra en la lista que cada sujeto escribió para cada categoría (por ejemplo, banano en la posición 1, manzana en la posición 2, etc.). Estos rangos fueron calculados para cada palabra, por separado, en los estratos socioeconómicos bajos (1-3) y los estratos socioeconómicos altos (4-6).
El objetivo de utilizar en la investigación la correlación de Pearson, es observar si los rangos de aparición de las palabras en cada categoría son similares en ambos grupos socioeconómicos; es decir, si según la palabra los rangos ascienden y descienden de igual manera en ambos grupos. Cuanto más se acerca el valor de la correlación de Pearson a 1, más estrecha es la relación existente entre los datos obtenidos en ambos grupos (véase figura 1).
Como se puede apreciar en la última columna de la derecha, la correlación de Pearson realizada entre los dos grupos socioeconómicos, muestra un alto grado de correlación en todas las categorías, lo cual es ratificado por el promedio aritmético de los valores en la columna (0.964). Lo anterior implica que entre los estudiantes universitarios de Bogotá no se observan diferencias significativas en los procesos de categorización léxica según los estratos socioeconómicos. Para este análisis se usó el programa SPSS (figura 2).
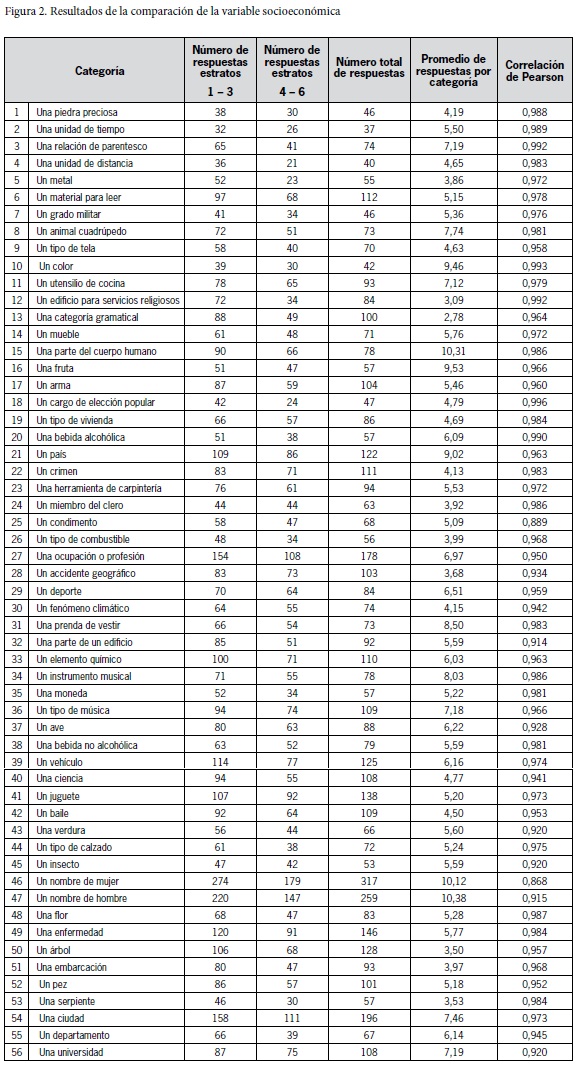
De acuerdo con los datos obtenidos, la categoría que presenta la mayor variación léxica entre los estratos es la número 25. Un condimento; sin embargo, en esta categoría se obtuvo un índice de correlación de 0,889. La proximidad de este valor a 1 indica que a pesar de que se presentaron algunas diferencias en los rangos de las palabras de esta categoría, en general, el léxico es muy similar en ambos grupos socioeconómicos. Considerando el alto grado de correlación entre las respuestas ofrecidas por los dos grupos socioeconómicos, se procederá, de ahora en adelante, a analizar los datos de todos los sujetos conjuntamente.
Comparación de los datos obtenidos en Valencia, España, con los datos obtenidos en Bogotá, Colombia
Los resultados obtenidos en el estudio en la ciudad de Bogotá fueron comparados con uno de los estudios realizados en España, en la ciudad de Valencia (Pascual, et. al., 1980). Aunque existen estudios más recientes (Goikoetxea, 2000), el estudio de Pascual es el que resulta más directamente comparable debido a las características de la población escogida, pues los sujetos con los que trabajó Goikoetxea fueron niños. Sin embargo, Pascual no utilizó todas las categorías usadas por Battig y Montague (1969), de hecho, eliminó algunas y combinó otras, por ejemplo, las categorías bebida alcohólica y bebida no-alcohólica fueron combinadas en la categoría bebidas.
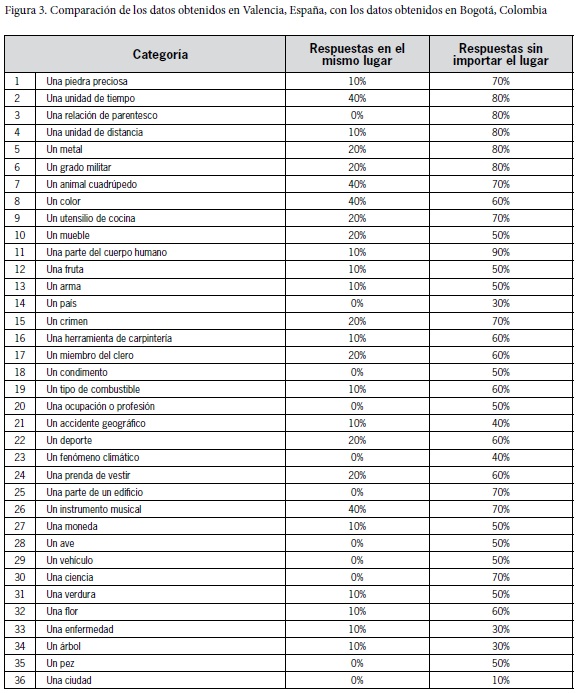
En la presente comparación, se tomaron las categorías que, a juicio de los autores, eran equivalentes. Así, se compararon 36 categorías cuyos resultados se pueden observar en la siguiente tabla. En la tercera columna está el porcentaje de respuestas que aparecen en el mismo rango de ambos corpus en los 10 primeros lugares de cada categoría. En la cuarta columna aparece el porcentaje de respuestas que se encontraban en los 10 primeros lugares de cada categoría en ambos corpus, independientemente del rango.
En la columna de respuestas, que compara los ítems sin importar el rango, podemos ver un alto nivel de coincidencia entre los datos obtenidos en las dos ciudades, ya que en la mayoría de los casos se observan porcentajes de correspondencia superiores al 50%. Esto quiere decir que a pesar de que los estudios fueron realizados con 29 años de diferencia y en regiones bastante distantes en el mundo hispano, las entradas léxicas más comunes son, en buena medida, las mismas.
Sin embargo, si se observa la columna en la que se muestra la correspondencia en el rango, nos podemos dar cuenta que los porcentajes son muy bajos, con una moda de 10% y una media de 13%. Esto quiere decir que, si bien las entradas léxicas son bastante similares, el nivel de tipicalidad de cada entrada no coincide en las dos ciudades. Evidentemente, en los campos semánticos con un número bajo y cerrado de entradas lexicales, el nivel de coincidencia, como era de esperarse, fue mayor, como por ejemplo en el caso de una unidad de tiempo o un color.
Hay algunos casos en los cuales el bajo o nulo nivel de coincidencia es fácilmente explicable, pues se trata de elementos léxicos estrechamente vinculados con las regiones en las que se realizaron los estudios, como en una ciudad o un país. En categorías en las cuales hay elementos que se pueden relacionar con la cultura vernácula de los sitios donde se realizaron los estudios, se puede ver una variación, tal es el caso de categorías como un árbol o una verdura, en las cuales los niveles de coincidencia son relativamente bajos (véase figura 3).
Discusión
El objetivo de este trabajo consistió en determinar las normas categoriales correspondientes al español de Bogotá, Colombia. Estas normas categoriales se recogieron siguiendo, en la medida de lo posible, el protocolo y la metodología propuestos por Battig y Montague (1969) de manera tal que los resultados puedan ser utilizados en ulteriores estudios y análisis. Además, se hizo una breve comparación de los datos obtenidos en Colombia con aquellos hallados para el español hablado en la ciudad de Valencia, España.
Los estudios de normas categoriales nos permiten captar las diferencias y similitudes entre normas en distintos lugares y en diversos idiomas; además de permitirnos establecer el inventario de los ítems lexicales más usados para cada categoría. Los resultados de esta investigación servirán, sin lugar a dudas, para la futura realización de experimentos de reconocimiento lexical y semántico, tanto en investigaciones teóricas, como en investigaciones aplicadas en el campo de la terapia del lenguaje.
En el análisis de los datos, pudimos encontrar que las entradas léxicas no muestran diferencias significativas cuando se examina la variable grupo socio-económico entre los estudiantes de diferentes universidades. Así pues, las normas categoriales son estables a través de los diversos sociolectos en la ciudad de Bogotá.
Este estudio demuestra una relativa estabilidad de las entradas léxicas halladas en el español valenciano y el español bogotano, como lo demuestra el 58% de coincidencia en las 10 primeras palabras de cada categoría, sin importar el rango. Esto resulta muy interesante, dada la distancia tanto geográfica como social de los dos corpus.
Es necesario estimular la realización de estudios similares al presente, en los cuales se examinen las normas categoriales para otros dialectos del español colombiano y latinoamericano. Además, sería altamente productivo llevar a cabo estudios comparativos entre diversos grupos etáreos y lingüísticos (por ejemplo, grupos de hablantes del español de zonas rurales, afrodescendientes, habitantes de calle, etc.) y con poblaciones con distintos niveles de instrucción. También se podría considerar la procedencia de los participantes y de su grupo familiar; sin embargo, esta variable no ha sido tomada en cuenta en ningún estudio de norma categorial de aquellos revisados en el transcurso de la investigación.
A continuación, se presentarán–por razones de espacio–45 de las 56 categorías de manera individual con la respectiva sistematización de datos. El objetivo de estas tablas es ofrecer los resultados obtenidos en cada categoría. Las palabras presentadas se organizaron según el número de veces que los sujetos las repitieron, es decir, la palabra más común aparece en la parte superior de la tabla y la menos común en la parte inferior. La información en estas tablas está organizada como se explica en la figura 4.
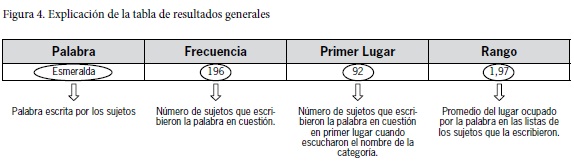
El dato numérico correspondiente al rango de las palabras, es decir, el promedio del lugar que ocupa cada palabra en la lista escrita por cada sujeto, solamente se mostrará para aquellas palabras que hayan sido escritas por 10 informantes o más, en una categoría determinada. No se incluyen en estas tablas las palabras escritas por menos de 10 informantes.







Pie de página
3En Colombia, los habitantes saben perfectamente a qué estrato socioeconómico pertenecen, pues éste afecta las tarifas de los servicios públicos y el acceso o no a ciertos beneficios estatales. Las viviendas están estratificadas del uno al seis, siendo el seis el más alto.
Bibliografía
Battig, W. F. y Montague, W. E. (1969). 'Category norms of verbal items in 56 categories: A replication and extension of the Connecticut category norms'. Journal of Experimental Psychology, 80, 1-46.
Dubois, D. y Poitou, J. (2002). 'Normes catégorielles pour 22 catégories sémantiques du français et 10 catégories sémantiques de l'allemand'. Cahiers du LCPE, 5, 35-118.
Goikoetxea, E. (2000). 'Frecuencia de producción de las respuestas a 52 categorías verbales en niños de primaria'. Psicológica, 21, 61-89.
Mateus, G. y Santiago, A. (2006). 'Disponibilidad léxica en estudiantes bogotanos'. Folios, 24, 3-26. Bogotá: Universidad Pedagógica Nacional.
Pascual, J. L. y Musitu, G. O. (1980). Normas categoriales. Psicológica, 1, 157-174.
Ruts, W., De Deyne, S., Ameel, E., Vanpaemel, W., Verbeemen, T. y Storms, G. (2004). 'Dutch norm data for 13 semantic categories and 338 exemplars'. Behavior Research Methods, Instruments, y Computers. 36 (3), 506-515.
Yoon, C., Feinberg, F., Hall, A., Hedden, T., Chen, H., Jing, Q., Cui, Y., y Park, D. (2004). 'Category Norms as a Function of Culture and Age: Comparisons of Item Responses to 105 Categories by American and Chinese Adults'. Psychology and Aging. Vol. 19, n°. 3, 379-393.
Licencia
Derechos de autor 2011 Revista Folios

Esta obra está bajo una licencia internacional Creative Commons Atribución-NoComercial 4.0.
Todo el trabajo debe ser original e inédito. La presentación de un artículo para publicación implica que el autor ha dado su consentimiento para que el artículo se reproduzca en cualquier momento y en cualquier forma que la revista Folios considere apropiada. Los artículos son responsabilidad exclusiva de los autores y no necesariamente representan la opinión de la revista, ni de su editor. La recepción de un artículo no implicará ningún compromiso de la revista Folios para su publicación. Sin embargo, de ser aceptado los autores cederán sus derechos patrimoniales a la Universidad Pedagógica Nacional para los fines pertinentes de reproducción, edición, distribución, exhibición y comunicación en Colombia y fuera de este país por medios impresos, electrónicos, CD ROM, Internet o cualquier otro medio conocido o por conocer. Los asuntos legales que puedan surgir luego de la publicación de los materiales en la revista son responsabilidad total de los autores. Cualquier artículo de esta revista se puede usar y citar siempre que se haga referencia a él correctamente.


















